Análisis de sentimiento e interacción en los Tweets de Pedro Castillo Terrones
Este estudio pretende descubrir la carga sentimental que poseen los tweets de Pedro Castillo y cuáles logran una mayor interacción con la población, para ello utilizaremos el entorno y lenguaje de programación R.

Herramientas
- R
- rtweet
- ggplot2
Recolección de datos
Los datos serán obtenidos mediante la API de Twitter con la librería rtweet, para ello es necesario registrarse en la aplicación y obtener las credenciales en la sección desarrolladores, de forma predeterminada solo se puede acceder a información pública de los tweets y usuarios.
twitter_tokens
<- create_token(app = "", consumer_key = "", consumer_secret = "")
Una vez autenticados pasamos a recolectar los tweets.
castillovar <- get_timeline("PedroCastilloTe", n = 4000)Seleccionaremos la variable de interés y guardamos los datos en un archivo .csv:
castillovar <- castillovar[c("created_at", "text", "favorite_count", "retweet_count")]
num_rows = nrow(castillovar)
#Crear vector de columna ID
X <- c(1:num_rows)
#Enlazar la columna ID al marco de datos
castillovar <- cbind(X , castillovar)write_as_csv(castillovar, "castillovar.csv")Con 'readr' cargamos el archivo .csv
library(readr)
castillovar <- read_csv("castillovar.csv")
castillovarPreparación de los datos
Una pieza central para un análisis de texto (text mining) es el tokenizado. La tokenización es una forma de separar un fragmento de texto en unidades más pequeñas llamadas tokens. Aquí, los tokens pueden ser palabras, caracteres o subpalabras. Por lo tanto, la tokenización se puede clasificar ampliamente en 3 tipos: tokenización de palabra, carácter y subpalabra (caracteres n-grama).
Utilizaremos 'string' y 'stringr' para la manipulación de caracteres, 'dplyr' para la manipulación del data frame, magrittr para el uso de pipes y tidytext para el tokenizado y el análisis de texto.
library(stringi)
library(stringr)
library(dplyr)
library(magrittr)
library(tidytext)
# Quitamos los acentos a los tweets.
castillovar$text <- stri_trans_general(castillovar$text, "Latin-ASCII")
# Limpiamos la variable text de algunos elementos innecesarios y tokenizamos.
replace_reg <- "https://t.co/[A-Za-z\\d]+|http://[A-Za-z\\d]+|&|<|>|RT|https"
unnest_reg <- "([^A-Za-z_\\d#@']|'(?![A-Za-z_\\d#@]))"
castillovar_t <- castillovar %>%
filter(!str_detect(text, "^RT")) %>%
mutate(text = str_replace_all(text, replace_reg, "")) %>%
unnest_tokens(word, text, token = "regex", pattern = unnest_reg) # Tokenizado
rm(replace_reg, unnest_reg)
El resultado es DataFrame más grande, de 42751 observaciones, Donde se reemplaza la columna (variable) text por word, manteniendo la variable X como ID:
str(castillovar_t)
El siguiente problema es que las palabras con mayor frecuencia son, como era de esperarse, artículos, preposiciones, conjunciones, y otros similares:
library(ggplot2)
freq1 <- castillovar_t %>%
count(word, sort = TRUE)
head(freq1, n = 30) %>%
ggplot(aes(reorder(word, n), n)) +
geom_bar(stat="identity", fill="#1a3a56") +
coord_flip() +
xlab("Palabras más usadas") +
ylab("Número") +
theme_minimal()
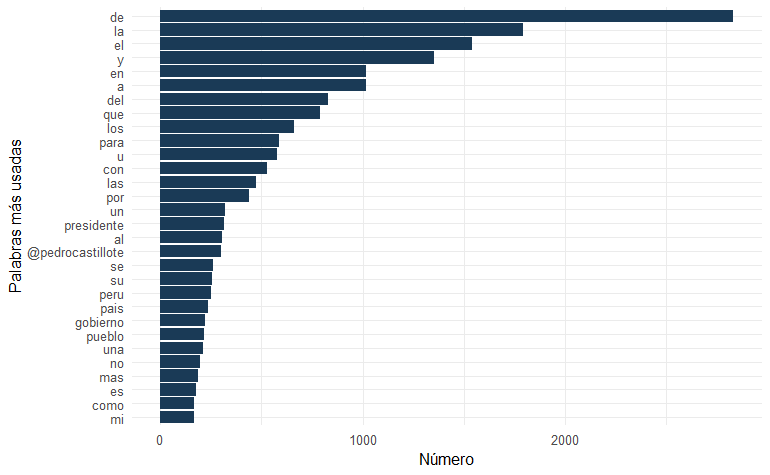
Esas palabras no agregan ninguna información relevante para entender la polaridad de los sentiments, son “palabras vacías” que debemos filtrar. Para ello necesitamos una lista de ese tipo de palabras en español que extraeremos del paquete stopwords:
library(stopwords)
#crear una lista de palabras vacias en español
stopwords_ES <- tibble(stopwords("spanish"))
colnames(stopwords_ES) <- "word"
#Agregamos algunas palabras vacias adicionales (lugares y monedas, etc.)
custom_stop <- tibble(word = c("lima", "cajamarca", "peru", "0001f134","0001f534", "dolar", "sol", "derecha", "u", "@pedrocastillote", "primero", "0001f1ea", "0001f1f5", "mas", "presidente","hoy", "fe0f", "#siempreconelpueblo","#palabrademaestro"))
stopwords_ES <- bind_rows(custom_stop, stopwords_ES)
rm(custom_stop)
#filtrado con la lista de palabras vacias
castillovar_tf <- castillovar_t %>%
filter(!word %in% stopwords_ES$word,
str_detect(word, "[a-z]"))
str(castillovar_tf)
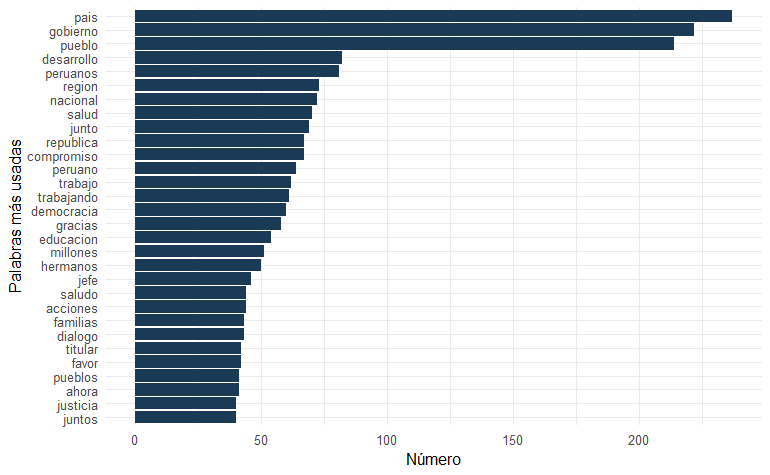
Ahora sí podemos observar las palabras más utilizadas por Pedro Castillo (@PedroCastilloTe):
freq2 <- castillovar_tf %>%
count(word, sort = TRUE)
head(freq2, n = 30) %>%
ggplot(aes(reorder(word, n), n)) +
geom_bar(stat="identity", fill="#1a3a56") +
coord_flip() +
xlab("Palabras más usadas") +
ylab("Número")+
theme_minimal()
Análisis de datos
El análisis de sentimiento nos permite aproximarnos a la intención emocional de los tweets que lanza el presidente Pedro Castillo. Este tipo de análisis puede basarse en el análisis de palabras o relaciones de palabras (n-gramas) y se pueden evaluar diferentes escalas de sentimiento (binarias, ponderadas, etc.).
Elegimos el enfoque de “bolsa de palabras”, el nivel del unigrama y la escala binaria, como una primera aproximación expedita. Ahora bien, existen diversos métodos para evaluar los sentiments en los textos, desde la anotación manual hasta el uso de machine learning, pero aquí utilizaremos el método basado en diccionario (Silge y Robinson 2017).
Este método conste en utilizar un diccionario en formato clave:valor para evaluar cada palabra. Se considera al tweet como una combinación de palabras individuales que tienen una carga emocional y la proporción de esas palabras nos da el sentimiento general del tweet, como posteriormente reflejaremos en un indice de sentimiento.
Los diccionarios para análisis de sentimiento en español son escasos y poco desarrollados. Después de una larga búsqueda pudimos encontrar el diccionario iSol que está formado por 8135 palabras, 2.509 positivas y 5.626 negativas, dejando a un lado las palabras emocionalmente neutras. Este diccionario a su vez está basado en otro diccionario en inglés bastante testeado como es el de Bing Liu, siendo una traducción especializada y mejorada.
#cargamos y adecuamos el diccionario al formato requerido.
negativas <- read_csv("isol/negativas_mejorada.csv", col_names = "word") %>%
mutate(sentiment = "negativo")
positivas <- read_csv("isol/positivas_mejorada.csv", col_names = "word") %>%
mutate(sentiment = "positivo")